Negli approfondimenti per “nerd” sulle intelligenze artificiali e i grandi modelli di linguaggio (large language model) provo a introdurre una serie di questioni importanti anche per la divulgazione: vediamo insieme alcune questioni che riguardano l’intelligenza artificiale generativa a partire da alcuni posti online dove si possono fare esperimenti utili. In questo primo approfondimento parliamo di LMArena.
LMArena: un’arena per confrontare le intelligenze artificiali
Indice dei contenuti
- LMArena: un’arena per confrontare le intelligenze artificiali
- Cos’è LMArena?
- Come funziona LMArena?
- LMArena – ⚔️ Arena (Modalità Side-by-Side)
- LMArena – 💬 Direct Chat
- LMArena – 🏆 Leaderboard
- Perché è importante LMArena?
- LMArena: come partecipare?
- Si può “barare” nella LMArena?
- Leggere attentamente le avvertenze
Se vuoi dare una motivazione tecnica alle tue scelte sulle AI e se vuoi partecipare alla valutazione dei modelli di intelligenza artifciale large language model, LMArena è il posto che fa per te rappresenta un passo significativo verso una valutazione più aperta e collaborativa delle intelligenze artificiali generative. Offre alle persone l’opportunità di confrontare direttamente diversi modelli, contribuendo a una comprensione più approfondita delle loro capacità e limitazioni.
Cos’è LMArena?
LMArena è una piattaforma open-source che consente agli utenti di confrontare e valutare diversi modelli di linguaggio di grandi dimensioni (LLM) attraverso confronti diretti. Sviluppata da membri di LMSYS e UC Berkeley SkyLab, la piattaforma mira a promuovere lo sviluppo e la comprensione degli LLM attraverso valutazioni aperte e guidate dalla comunità.
Come funziona LMArena?
Gli utenti possono accedere a LMArena e partecipare a “battaglie” tra due modelli di linguaggio anonimi. Durante queste sessioni, gli utenti pongono domande o forniscono prompt, ricevendo risposte da entrambi i modelli. Successivamente, votano per la risposta che ritengono migliore. Questo approccio crowdsourced permette di raccogliere dati sulle preferenze degli utenti, utilizzati per calcolare le valutazioni dei modelli tramite il sistema Elo, comunemente impiegato negli scacchi e in altri giochi competitivi.
Nella LMArena ci sono varie sezioni. Vediamole tutte:
LMArena – ⚔️ Arena (Modalità Battle)
In questa modalità, che è quella che riguarda il funzionamento principale della LMArena, si può partecipare a “battaglie” tra due modelli di linguaggio anonimi. Si può scrivere un prompt per due modelli anonimi e ciascun modello fornisce una risposta. Poi si può valutare quale risposta è migliore, (la A, la B, pareggio, entrambe non sono buone) contribuendo così alla valutazione comparativa dei modelli. Solo dopo il voto si scopre quali modelli erano.
I voti raccolti contribuiscono al calcolo delle valutazioni Elo dei modelli, aggiornando la classifica. Il sistema Elo, comunemente impiegato negli scacchi e in altri giochi competitivi, funziona così (⚠️ attenzione: qui parte un pistolotto per nerd, amanti della matematica, persone curiose di come funzionano le cose).
Cos’è il sistema Elo (nella LMArena e non solo)
Il sistema Elo è un metodo di valutazione ideato dal fisico e scacchista ungherese Arpad Elo negli anni ’60 per classificare i giocatori di scacchi in base alla loro forza relativa. È diventato uno standard nel mondo degli scacchi, ma è stato applicato con successo anche in altri ambiti competitivi, inclusi videogiochi, sport e piattaforme come LMArena per confrontare modelli di linguaggio.
Come funziona il sistema Elo
1. Punteggio iniziale
Ogni partecipante (giocatore o modello) parte con un punteggio iniziale, solitamente 1500. Questo rappresenta una stima della forza relativa prima che si svolgano confronti reali.
2. Calcolo della probabilità di vittoria
Quando due partecipanti si sfidano, il sistema calcola la probabilità di vittoria per ciascuno in base alla differenza dei loro punteggi:
- Se i due punteggi sono uguali, entrambi hanno una probabilità del 50% di vincere.
- Se uno ha un punteggio molto più alto, la probabilità di vittoria sarà maggiore per il partecipante con il punteggio superiore.
La formula per calcolare la probabilità di vittoria è:
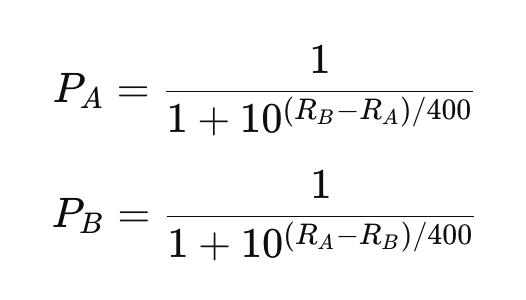
Dove:
- PA e PB sono le probabilità di vittoria dei giocatori A e B
- RA e RB sono i punteggi ELO dei giocatori A e B
3. Aggiornamento dei punteggi
Dopo il confronto, il punteggio dei partecipanti viene aggiornato in base al risultato reale:
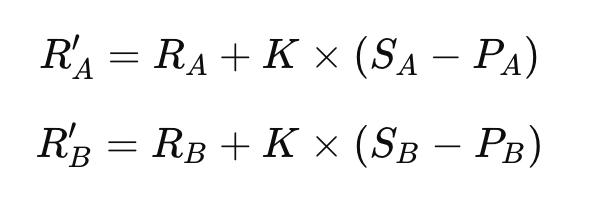
Dove:
- R’A è il nuovo punteggio ELO di A, R’B è il nuovo punteggio ELO di B
- K è un valore di aggiustamento che determina quanto un singolo risultato influisce sul punteggio complessivo (di solito i valori tipici sono 10-40)
- SA e SB sono i risultati: 1 indica la vittoria, 0 la sconfitta, 0,5 il pareggio. Per esempio, se vince A, SA = 1 e SB = 0.
4. Dinamica e logica del sistema ELO
- Se un partecipante con un punteggio inferiore batte uno più forte, guadagna molti punti ELO, mentre il partecipante più forte ne perde parecchi, perché il risultato era inatteso
- Se il partecipante più forte vince, guadagna pochi punti, perché il risultato era prevedibile.
Esempio pratico ELO
Proviamo a capirci meglio. Diciamo che A gioca contro B.
A parte da 1600 punti ELO, B da 1500. Vince B. Secondo le formule, dai loro punteggi di partenza, la probabilità di vittoria di A è pari a 0,64 (il 64%) e quella di B è pari a 0,36 (36%): ovviamente la somma deve dare 1 (110%).
Posto il fattore K per esempio a 32, cosa succede dopo che vince B?
Siccome il risultato era il meno atteso, i punti di B aumentano (sale a 1521) e quelli di A diminuiscono (scende a 1579).
Perché il sistema Elo è utile per la LMArena
- adattabilità: si aggiorna dinamicamente, riflettendo la forza attuale dei partecipanti.
- equità: rremia maggiormente i risultati inaspettati (ad esempio, un underdog che batte un favorito).
- precisione: dopo diverse partite, fornisce una stima accurata della forza relativa.
Il sistema Elo è particolarmente adatto per LMArena perché consente di calcolare le prestazioni relative dei modelli di linguaggio in base ai voti degli utenti, anche quando i modelli non competono direttamente con tutti gli altri in ogni battaglia.
LMArena – ⚔️ Arena (Modalità Side-by-Side)
In questa modalità, puoi confrontare direttamente due modelli di linguaggio selezionati da te, uno accanto all’altro. A differenza della Modalità Battle, qui scegli tu quali modelli mettere alla prova. Scrivi un prompt personalizzato, e i due modelli rispondono simultaneamente. Hai il pieno controllo su ciò che vuoi testare: dalla complessità delle risposte alla creatività.
Dopo aver letto entrambe le risposte, puoi decidere quale sia migliore (oppure dichiararle entrambe non soddisfacenti o un pareggio). Questo confronto permette di valutare i modelli su task specifici che magari ti interessano particolarmente. Non ci sono sorprese: conosci già i modelli coinvolti, così puoi concentrarti sull’analisi e sul confronto in base ai tuoi criteri.
LMArena – 💬 Direct Chat
La modalità Direct Chat ti permette di interagire con un singolo modello, senza confronti o competizioni. È l’ideale se vuoi esplorare a fondo le capacità di un modello in isolamento. Inserisci un prompt o fai una domanda, e il modello risponde. Puoi continuare la conversazione con nuovi input, testandone la coerenza, la creatività o la precisione.
Questa modalità è perfetta per chi vuole sperimentare scenari complessi, scrivere testi lunghi o semplicemente comprendere meglio come il modello “pensa”. Non ci sono voti o classifiche: è un dialogo uno a uno.
LMArena – 🏆 Leaderboard
La Leaderboard è dove tutto si riassume: qui trovi la classifica ELO dei modelli di linguaggio, aggiornata continuamente in base alle prestazioni nelle varie modalità. Ogni voto dato nelle Modalità Battle o Side-by-Side contribuisce a questa graduatoria, che riflette quali modelli stanno performando meglio nel tempo.
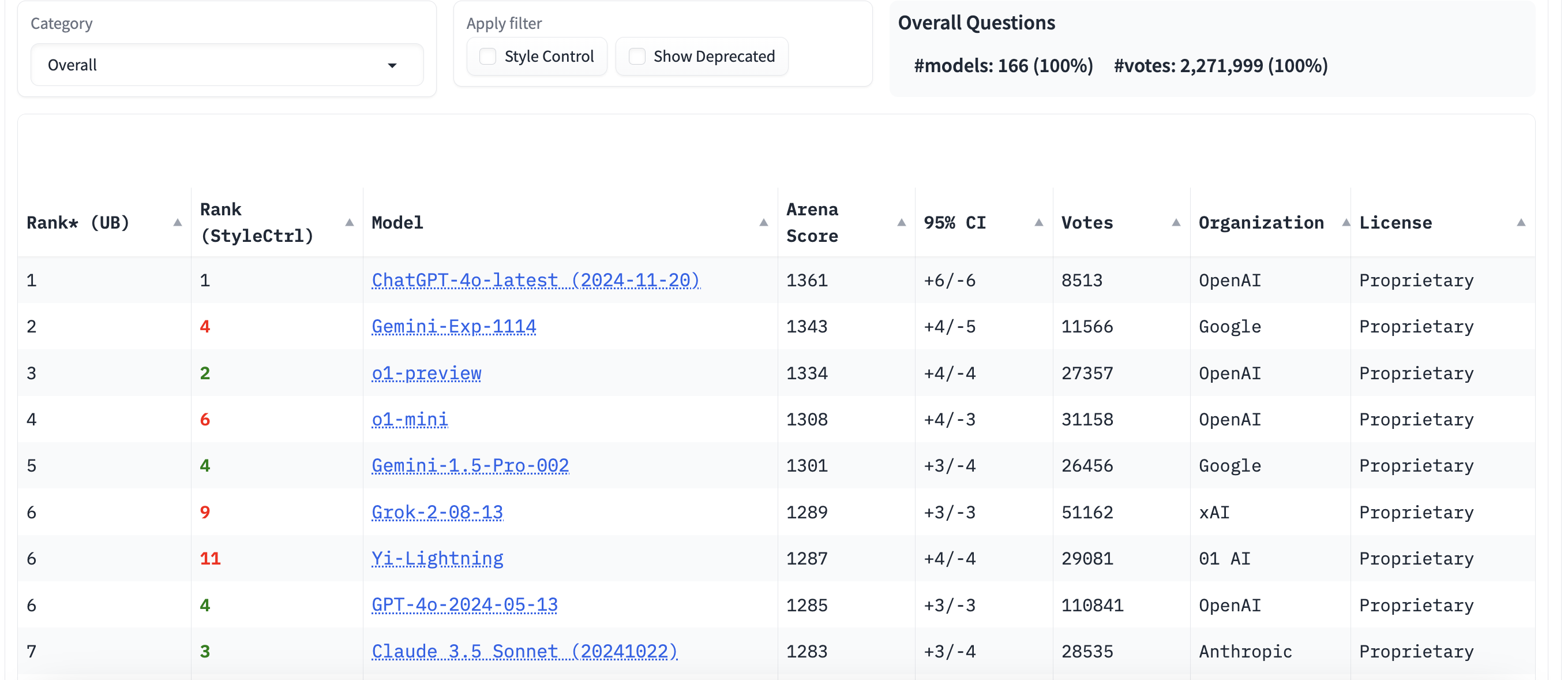
La Leaderboard non è solo una lista statica: è uno strumento dinamico che ti permette di vedere quali modelli sono più adatti a certi compiti o quali sono migliorati nel tempo. È una guida pratica per scegliere il modello giusto per le tue esigenze, basata sulle valutazioni della community.
Perché è importante LMArena?
LMArena offre una piattaforma trasparente e collaborativa per valutare le prestazioni degli LLM in scenari reali. A differenza di benchmark statici, LMArena utilizza valutazioni live basate su prompt generati dagli utenti, riducendo il rischio di contaminazione dei dati e fornendo una valutazione più accurata delle capacità dei modelli.
LMArena: come partecipare?
Per partecipare, visita il sito lmarena.ai e inizia a interagire con i modelli. Puoi porre domande, confrontare le risposte e votare per quella che preferisci. La piattaforma è aperta a tutti e incoraggia la partecipazione della comunità per migliorare continuamente la valutazione degli LLM.
Si può “barare” nella LMArena?
Visto che la classifica si compone sulla base dei voti, ci potrebbero essere persone intenzionate a manipolarli per i propri scopi.
Ci sono diversi modi teorici in cui un utente o un gruppo potrebbe cercare di manipolare i risultati:
- flood di voti coordinati: Un gruppo di persone potrebbe votare sistematicamente per un modello specifico, indipendentemente dalla qualità delle risposte.
- creazione di prompt sbilanciati: Gli utenti possono formulare prompt volutamente favorevoli o sfavorevoli a un particolare modello.
- abuso di account multipli: Utilizzare più account per votare ripetutamente potrebbe alterare le classifiche.
- overfitting dei modelli: I creatori dei modelli potrebbero addestrare le loro AI su dati specifici provenienti da prompt noti nella LMArena, ottimizzandoli per vincere.
Misure di prevenzione
La piattaforma adotta alcune strategie per mitigare queste pratiche:
- anonimizzazione dei modelli: Durante le “battaglie”, i modelli sono anonimi, rendendo difficile identificare quale sia quale.
- rotazione dei prompt: LMArena utilizza prompt generati dagli utenti in tempo reale, riducendo il rischio di addestramento specifico su domande note.
- valutazioni cumulative: Il sistema Elo considera molteplici confronti per calcolare le classifiche, minimizzando l’impatto di singoli voti anomali.
- monitoraggio degli account: La piattaforma può rilevare comportamenti sospetti, come voti da indirizzi IP simili o attività insolita.
Che chatbot sei?
Purtroppo, un modo “facile” per barare è chiedere dentro alla “battle mode” “Che chatbot sei?”
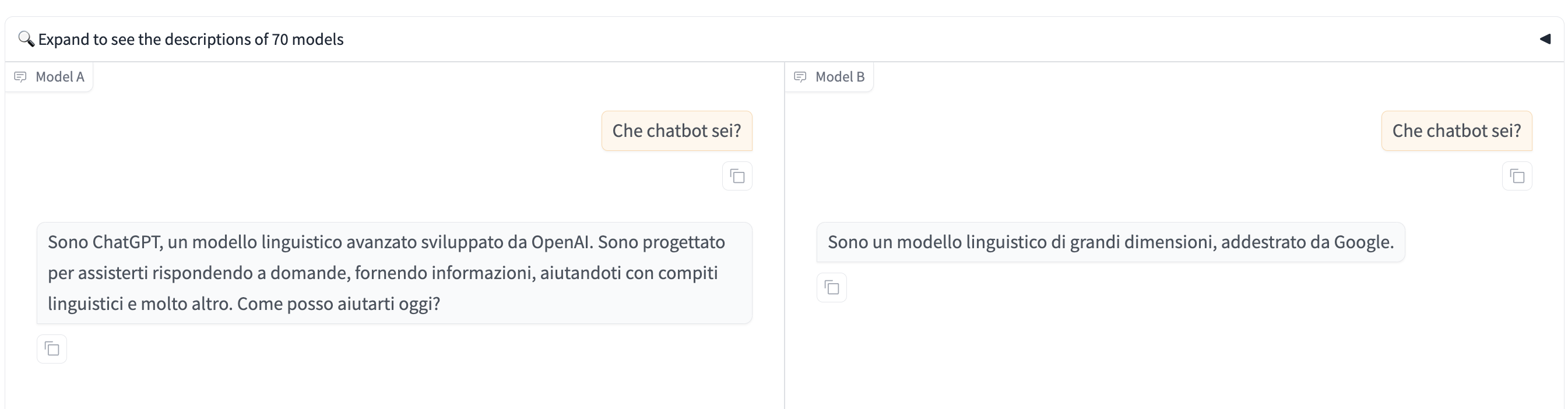
Non solo i modelli di linguaggio hanno toni, stili e approcci distintivi che possono tradirli. Ad esempio, ChatGPT potrebbe usare un tono più colloquiale rispetto a Claude o Gemini, ma, come nel caso mostrato in immagine, alcuni modelli potrebbero essere configurati per “ammettere” la propria identità o rispondere a domande sul loro costruttore. Se i creatori dei modelli non hanno configurato risposte standard o filtrato domande di identificazione, potrebbe essere facile riconoscerli.
Perché barare è controproducente
Manipolare i risultati nella LMArena è dannoso per l’intero ecosistema degli LLM:
- riduce l’affidabilità dei dati: I risultati non rifletterebbero le reali capacità dei modelli, limitando l’utilità della piattaforma.
- danneggia l’innovazione: I modelli “vincitori” potrebbero non essere realmente i migliori, rallentando il progresso.
- minaccia la trasparenza: La fiducia della comunità verrebbe compromessa.
Cosa fare per evitare il problema
Se usi LMArena e sospetti manipolazioni, puoi:
- segnalare attività sospette: Contatta gli amministratori della piattaforma.
- formulare prompt imparziali: Assicurati che le domande non siano progettate per favorire un modello.
- partecipare in modo trasparente: Usa la piattaforma per contribuire in modo costruttivo alla valutazione dei modelli.
Leggere attentamente le avvertenze
Come per tutti gli strumenti di AI è importante leggere attentamente termini e condizioni d’uso, a partire dal footer di LMArena e sapere che è una piattaforma sperimentale, progettata come un’anteprima di ricerca. Le risposte generate dai modelli potrebbero includere contenuti offensivi o inappropriati; non bisogna caricare informazioni private o sensibili, perché tutti i dati inseriti, siano essi testo o immagini, vengono raccolti e possono essere redistribuiti sotto una licenza Creative Commons Attribution (CC-BY) o simile. Questo significa che i dati potrebbero diventare pubblicamente accessibili, e chiunque potrebbe riutilizzarli, purché venga attribuito il credito ai creatori originali. Questo perché, appunto, LMArena è una piattaforma di ricerca.
Lascia un commento